Return to routine and a paw promise my AI story
A journey of work home paws and peace of mind. This is a story how I experimented with AI,raspberry pi to help my furry friend to be calm when I am not at home.
AI you say

My Bernedoodle barks whenever he’s left alone. He hates being without anyone to cuddle and often gets anxious or bored when there’s no one around. To help keep him occupied, I’ve set up an AI-powered Raspberry Pi to play sounds for him while I’m away.
My Journey: Items needed for setup
- Modern HDMI enabled TV/Monitor or speakers
- Raspberry Pi5
- Microphone HDMI enabled ,I used https://www.logitech.com/en-us/shop/p/brio-100-webcam.960-001580
- USB keyboard and mouse
- Internet Connectivity
- Basic Python know how
Steps
Install Raspberry Pi OS on SD card,Follow https://bipulkkuri.medium.com/prepping-the-pi-986aed53bb71
Connect keyboard mouse microphone/webcam(with microphone) to pi
Connect Pi5 to Monitor and enable SSH via
Access configuration: Go to the start menu, then “Preferences” > “Raspberry Pi Configuration”.
- Navigate to Interfaces: Select the “Interfaces” tab.
- Enable SSH: Toggle the “SSH” option to “On
Login to pi5 , via remote SSH and List sound devices on pi5
mkdir rtopaws
cd rtopaws
sudo apt update
sudo apt-get install libportaudio2
# Install Python dependencies.
python -m venv env
source env/bin/activate
echo "mediapipe" > requirements.txt
python -m pip install pip --upgrade
python -m pip install -r requirements.txtVerify the devices are detected
#listsounddevices.py
import sounddevice
devs = sounddevice.query_devices()
print(devs) # Shows current output and input as well with "<" abd ">" tokens
for dev in devs:
print(dev['name'])pip install sounddeviceRun to get the list of deviced detected
python listsounddevices.py
0 vc4-hdmi-0: MAI PCM i2s-hifi-0 (hw:0,0), ALSA (0 in, 2 out)
1 Brio 100: USB Audio (hw:2,0), ALSA (1 in, 0 out)
2 sysdefault, ALSA (0 in, 128 out)
3 hdmi, ALSA (0 in, 2 out)
4 pulse, ALSA (32 in, 32 out)
* 5 default, ALSA (32 in, 32 out)
vc4-hdmi-0: MAI PCM i2s-hifi-0 (hw:0,0)
Brio 100: USB Audio (hw:2,0)
sysdefault
hdmi
pulse
defaultRecord your voice commands on raspberry pi , recorded 3 sec audio on Brio device (hw:2,0)
arecord -D plughw:2,0 --duration=3 goplace.wavThis should create a wav file in current dir
Lets test out the recorded file to play from python
#aplay.py
import pygame
from time import sleep
import pygame._sdl2.audio as sdl2_audio
import sys
pygame.mixer.init()
print(sdl2_audio.get_audio_device_names(False))
devices=tuple(sdl2_audio.get_audio_device_names(False))
#get the first device
device=devices[0]
print(device)
pygame.mixer.quit()
pygame.mixer.init(devicename=device)
filetoPlay=sys.argv[1]
pygame.mixer.music.load(filetoPlay)
pygame.mixer.music.play()
sleep(2)
pygame.mixer.quit()Play the file
python aplay.py goplace.wav
pygame 2.6.1 (SDL 2.28.4, Python 3.11.2)
Hello from the pygame community. https://www.pygame.org/contribute.html
['Built-in Audio Digital Stereo (HDMI)']
Built-in Audio Digital Stereo (HDMI)Next lets use mediapipe from google to do bark detection i.e (audio classification),Download the yamnet.tflite model
wget -O yamnet.tflite -q https://storage.googleapis.com/mediapipe-models/audio_classifier/yamnet/float32/1/yamnet.tfliteHere is the code which does classification
# Copyright 2023 The MediaPipe Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Main scripts to run audio classification."""
import argparse
import time
import subprocess
import sys
from mediapipe.tasks import python
from mediapipe.tasks.python.audio.core import audio_record
from mediapipe.tasks.python.components import containers
from mediapipe.tasks.python import audio
#from utils import Plotter
def run(pet:str,fileToPlay:str,sensitiveLevel: float ,model: str, max_results: int, score_threshold: float,
overlapping_factor: float) -> None:
"""Continuously run inference on audio data acquired from the device.
Args:
model: Name of the TFLite audio classification model.
max_results: Maximum number of classification results to display.
score_threshold: The score threshold of classification results.
overlapping_factor: Target overlapping between adjacent inferences.
"""
if (overlapping_factor < 0) or (overlapping_factor >= 1.0):
raise ValueError('Overlapping factor must be between 0.0 and 0.9')
if (score_threshold < 0) or (score_threshold > 1.0):
raise ValueError('Score threshold must be between (inclusive) 0 and 1.')
# Initialize a plotter instance to display the classification results.
#plotter = Plotter()
classification_result_list = []
def save_result(result: audio.AudioClassifierResult, timestamp_ms: int):
result.timestamp_ms = timestamp_ms
classification_result_list.append(result)
# Initialize the audio classification model.
base_options = python.BaseOptions(model_asset_path=model)
options = audio.AudioClassifierOptions(
base_options=base_options, running_mode=audio.RunningMode.AUDIO_STREAM,
max_results=max_results, score_threshold=score_threshold,
result_callback=save_result)
classifier = audio.AudioClassifier.create_from_options(options)
# Initialize the audio recorder and a tensor to store the audio input.
# The sample rate may need to be changed to match your input device.
# For example, an AT2020 requires sample_rate 44100.
buffer_size, sample_rate, num_channels = 15600, 16000, 1
audio_format = containers.AudioDataFormat(num_channels, sample_rate)
record = audio_record.AudioRecord(num_channels, sample_rate, buffer_size)
audio_data = containers.AudioData(buffer_size, audio_format)
# We'll try to run inference every interval_between_inference seconds.
# This is usually half of the model's input length to create an overlapping
# between incoming audio segments to improve classification accuracy.
input_length_in_second = float(len(
audio_data.buffer)) / audio_data.audio_format.sample_rate
interval_between_inference = input_length_in_second * (1 - overlapping_factor)
pause_time = interval_between_inference * 0.1
last_inference_time = time.time()
# Start audio recording in the background.
record.start_recording()
# Loop until the user close the classification results plot.
while True:
# Wait until at least interval_between_inference seconds has passed since
# the last inference.
now = time.time()
diff = now - last_inference_time
if diff < interval_between_inference:
time.sleep(pause_time)
continue
last_inference_time = now
# Load the input audio from the AudioRecord instance and run classify.
data = record.read(buffer_size)
# audio_data.load_from_array(data.astype(np.float32))
audio_data.load_from_array(data)
classifier.classify_async(audio_data, time.time_ns() // 1_000_000)
# Plot the classification results.
if classification_result_list:
#print(classification_result_list)
top_category=classification_result_list[0].classifications[0].categories[0]
if(top_category.category_name==pet and top_category.score>sensitiveLevel):
print(f' === found: {top_category.category_name} Score: {top_category.score:.2f}')
subprocess.run(['python','aplay.py',fileToPlay])
#plotter.plot(classification_result_list[0])
classification_result_list.clear()
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument(
'--pet',
help='Pet catagory',
required=False,
default='Dog')
parser.add_argument(
'--playfile',
help='Pet command',
required=False,
default='goplace.wav')
parser.add_argument(
'--sensitive',
help='sensitive level',
required=False,
default='0.6')
parser.add_argument(
'--model',
help='Name of the audio classification model.',
required=False,
default='yamnet.tflite')
parser.add_argument(
'--maxResults',
help='Maximum number of results to show.',
required=False,
default=5)
parser.add_argument(
'--overlappingFactor',
help='Target overlapping between adjacent inferences. Value must be in (0, 1)',
required=False,
default=0.5)
parser.add_argument(
'--scoreThreshold',
help='The score threshold of classification results.',
required=False,
default=0.0)
args = parser.parse_args()
run(args.pet,args.playfile,float(args.sensitive),args.model, int(args.maxResults), float(args.scoreThreshold),
float(args.overlappingFactor))
if __name__ == '__main__':
main()Key thing in the code ,when category is dog and sensitive level is greater than 0.6 play the wav file as a subprocess run this in loop
if(top_category.category_name==pet and top_category.score>sensitiveLevel):
print(f' === found: {top_category.category_name} Score: {top_category.score:.2f}')
subprocess.run(['python','aplay.py',fileToPlay])Running the code , with a dog bark
python classify.py
Error in cpuinfo: prctl(PR_SVE_GET_VL) failed
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
W0000 00:00:1741712430.671910 16620 inference_feedback_manager.cc:114] Feedback manager requires a model with a single signature inference. Disabling support for feedback tensors.
W0000 00:00:1741712431.707948 16620 time_series_util.cc:52] Timestamp 1741712431.707000 not consistent with number of samples 15600 and initial timestamp 1741712431217000. Expected timestamp: 1741712432.192000 Timestamp difference: -0.485000 sample_rate: 16000.000000
=== found: Dog Score: 0.94
pygame 2.6.1 (SDL 2.28.4, Python 3.11.2)
Hello from the pygame community. https://www.pygame.org/contribute.html
['Built-in Audio Digital Stereo (HDMI)']
Built-in Audio Digital Stereo (HDMI)
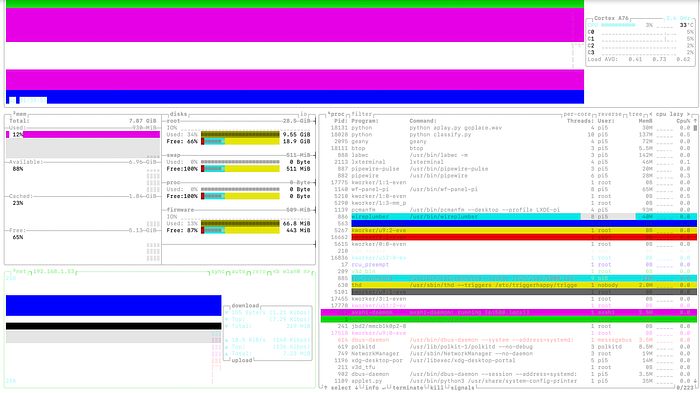
and system usage, you can see both aplay and classify python files executing with near 0 and 0.5% CPU usage
This can be enhanced to play calming music via youtube api or treat disposal, trigger call to Pet sitter
